
分布式 ID 生成算法 SnowFlake 及其 Go 实现
分布式 ID 生成算法 SnowFlake 及其 Go 实现
在先前总结我 GSOC 2023 项目的文章中,我提到了 Python agent 的 ID 生成是主要的性能瓶颈。我的 Mentor 为了解决这个问题,专门提了一个 issue ,其主要内容就是将 Skywalking Python agent 的 ID 生成规则和 Java agent 一致。他在写这个 PR 的时候也有和我讨论参考我的意见,我也就这个机会进一步了解了著名的分布式 ID 生成算法 SnowFlake。
在我 Mentor 的这个 PR 中,他实际上是以雪花算法(SnowFlake 算法)的思想来生成唯一 ID ,具体实现和应用场景还是和原版雪花算法有很多不同。而我这篇博客的主要目的,还是在于记录雪花算法的主要原理,并以百度开源的一个 ID 生成器为例子来进一步说明。最后,我也给出我自己写的代码——通过 Go 实现百度 ID 生成器的部分内容。
SnowFlake - 雪花算法
SnowFlake 原先是 Twitter(现 X) 开源的分布式 ID 生成算法,源代码已经不再维护,为仅可读状态。该算法将一个 64 位的 UUID(Universally Unique Identifier) 拆分成如下部分:
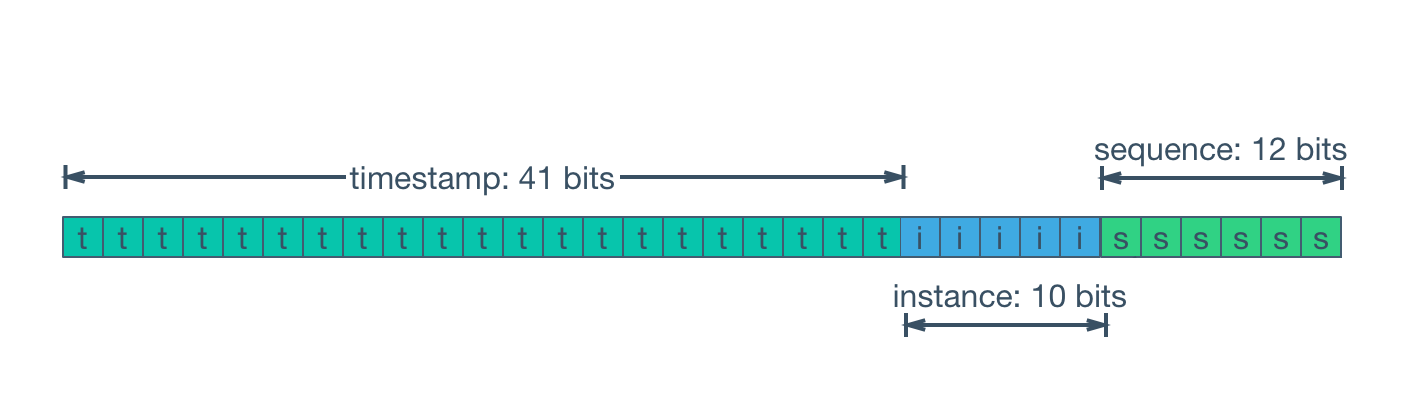
- 首位 : 固定为 0 作为占位,因为往往用 long 存储雪花 ID,而大部分计算机第一位 0 表示整数,1 表示复数
- 时间戳 : 41 bits,毫秒精度。(依照 UNIX 时间,时间戳从协调世界时 1970 年 1 月 1 日 0 时 0 分 0 秒开始,因此可自定义的时间共 69 年。)
- 物理机器标识码 : 10 bits,可最多支持 1024 台机器
- 序列号 : 12 bits,每台机器每 4096 位滚动一次(有保护功能,避免在同一毫秒内滚动从而产生重复 ID 的情况——因为 UNIX 时间是以毫秒为单位的)
实际上在生产过程中,每个部分所占位比重可以灵活变通。时间戳方面,可以以工程项目起始时间为基准,记录相对时间戳,例如我的项目 A 是 2020.1.1 启动的,那么项目 A 的雪花 ID 的时间戳部分都可以设置为与之对应的相对 UNIX 时间,这样以来也可以缩小时间戳部分的比特位数,为其它部分腾出空间;物理机器标识码当然也可以根据实际的物理机器/虚拟化容器数量来配置;序列号则应当在保证其它部分可用的情况下尽量长,减少毫秒内滚动。
SnowFlake 算法 ID 具有如下特征:
- 全局唯一性:雪花算法可以保证集群系统的 ID 全局唯一
- 趋势递增:由于强依赖时间戳,所以整体趋势会随着时间递增
- 不满足单调递增:在不考虑时间回拨的情况下,虽然在单机中可以保持单调递增,但在分布式集群中无法做到单调递增,只能保证总体趋势递增
- 信息安全:指的是 ID 生成不规则,无法猜测下一个生成的 ID
SnowFlake 算法以其简单、高性能、无需额外依赖而闻名,但它还是存在几个问题:
服务器时间回拨 : 由于雪花算法严重依赖系统时间,所以当发生服务器时钟回拨的问题时可能产生重复的 ID。
机器 ID 分配 :机器 ID 需要单独分配,业内目前普遍采用 zookeeper 或数据库方式,但是没有合理的分配和回收方案,存在浪费问题。
时间回拨问题的解决方案
由于雪花算法重度依赖机器的当前时间,所以一旦发生时间回拨,将有可能导致生成的 ID 可能与此前已经生成的某个 ID 重复(前提是生成 ID 时序列号也刚好一致)。
常见的解决方案如下:
抛出异常或延迟等待(缓解)
当算法检测到时钟回拨后,直接抛出异常;或者阻塞等待一段时间,再判断时钟是否追上来。这种方式简单粗暴,但是会影响服务可用性,只适用于并发量不高的系统。备用机高可用方案(避免)
通过备用机方案,当发现时钟回拨后,切换到备用机上继续生成 ID。这种方式可以保证服务可用性,但是需要额外的机器成本。时间戳脱离系统时间自增(避免)
如果时间戳字段不再依赖于系统时间,那么即使发生时钟回拨,也不会影响 ID 冲突。这种方案需要程序自动在每一毫秒内自增时间戳,每一毫秒内的序列号 seq 不会浪费,或者说是将所有时间戳字段都转化为了 seq 字段。局限性是很明显的,这个方案只有当系统对 ID 的时间戳功能没有需求,仅需要提供自增 ID 的情况下,才可以考虑。缓存序列号缓解时钟回拨问题(缓解)
这个方案并不能彻底解决时钟回拨,而是一个缓解方法。由于一个毫秒内序列号往往不能全部用完,因此我们可以将一定时间内(例如 2 秒)的序列号进行缓存。一旦发生了时钟回拨,那么就可以从缓存中获取未使用的序列号。这种方案可以保证服务短时可用性,但若时钟回拨时间超过缓存时间,仍然需要抛出异常,并且会破坏 ID 自增性。增加时钟回拨缓冲位(缓解)
参考: https://www.cnblogs.com/shoshana-kong/p/17319231.html
在该博客的实现方式中,采用从机器序列中取出的 3 个比特位作为时间序列缓冲位,当发生一次时间回拨事件则缓冲位加一,支持 8 次回拨事件的容错,当缓冲位达到 8 时,抛出异常。然而,这种方式仍然无法保证 ID 的单调递增性,因为当发生回拨事件时,时间戳位是跳跃而不是单调递增的。事实上,应当将三个缓冲位设在时间戳位之后(即第 63 - 61 位),这样才能保证 ID 的单调递增性不受时间戳跳跃的影响。类似的,也可以根据系统需求,调整时间戳位数、机器位数和序列号位数,随后增大缓冲位数。
这种方案会导致常态下有三个比特位的浪费,但是可以保证短时服务可用性,且不会破坏 ID 的单调递增性。

百度 UUID 生成器
以下以百度 UUID 生成器为例讲讲雪花算法的生产实践。
仓库地址:https://github.com/baidu/uid-generator
中文文档:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
具体图例、设计细节、性能测试请进入中文文档中进一步阅读,下文只给出基本的介绍与其对原始 SnowFlake 算法的改进。

sign (1bit)
固定 1bit 符号标识(值为 0),即生成的 UID 为正数。delta seconds (28 bits)
当前时间,相对于时间基点”2016-05-20”的增量值,单位:秒,最多可支持约 8.7 年worker id (22 bits)
机器 id,最多可支持约 420w 次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。sequence (13 bits)
每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
CachedUidGenerator 与 RingBuffer
在基本的 SnowFlake ID 生成算法之上,百度进一步封装了一个 CachedUidGenerator 。在这个生成器中,采用了一种被称为 RingBuffer 的环形数组数据结构作为缓存,数组每个元素成为一个 slot。RingBuffer 容量默认为 Snowflake 算法中 sequence 最大值,且必须为 2^N。
Tail 指针、Cursor 指针用于环形数组上读写 slot:
Tail 指针
表示 Producer 生产的最大序号(此序号从 0 开始,持续递增)。Tail 不能超过 Cursor,即生产者不能覆盖未消费的 slot。当 Tail 已赶上 curosr,此时可通过 rejectedPutBufferHandler 指定 PutRejectPolicyCursor 指针
表示 Consumer 消费到的最小序号(序号序列与 Producer 序列相同)。Cursor 不能超过 Tail,即不能消费未生产的 slot。当 Cursor 已赶上 tail,此时可通过 rejectedTakeBufferHandler 指定 TakeRejectPolicy
CachedUidGenerator 采用了双 RingBuffer,Uid-RingBuffer 用于存储 Uid、Flag-RingBuffer 用于存储 Uid 状态(是否可填充、是否可消费)
RingBuffer 有下述三种填充时机:
初始化预填充
RingBuffer 初始化时,预先填充满整个 RingBuffer 。即时填充
消费时,即时检查剩余可用 slot 量(tail - cursor),如小于设定阈值,则补全空闲 slots。这个阈值是可配置的。周期填充
通过 Schedule 线程,定时补全空闲 slots。可通过 scheduleInterval 配置,以应用定时填充功能,并指定 Schedule 时间间隔。
由于数组元素在内存中是连续分配的,可最大程度利用 CPU cache 以提升性能,但同时会带来 伪共享(FalseSharing) 问题,在这里百度通过了数据补齐的方式把它解决了。这是一个比较深层次且有趣的 CPU 性能优化问题,我还在不止一次地方遇到它,后续我会专门为其写一篇博客,这里不再赘述。
百度关于 UID 比特分配的建议
对于并发数要求不高、期望长期使用的应用,可增加 timeBits 位数,减少 seqBits 位数。例如节点采取用完即弃的 WorkerIdAssigner 策略,重启频率为 12 次/天,那么配置成 {"workerBits":23, "timeBits":31, "seqBits":9} 时,可支持 28 个节点以整体并发量 14400 UID/s 的速度持续运行 68 年。
对于节点重启频率频繁、期望长期使用的应用,可增加 workerBits 和 timeBits 位数,减少 seqBits 位数。例如节点采取用完即弃的 WorkerIdAssigner 策略,重启频率为 24*12 次/天,那么配置成 {"workerBits":27, "timeBits":30, "seqBits":6} 时,可支持 37 个节点以整体并发量 2400 UID/s 的速度持续运行 34 年。
Go 实现百度 UID 生成器
仓库地址:https://github.com/FAWC438/uid-generator-go
我根据百度的 uid-generator 利用 Go 重构了具体实现,实际上只是想顺便练习一下 Go 的语法和编写思想。但可惜在并发编程这边,Go 和 Java 的差异很大,而我对 Go 语言还完完全全只是一知半解的入门者,我最后也没能完全复现 Go 版本下的百度 uid-generator 的结果。不过我仍然还是大体上实现了基本的 Go 版本的雪花算法,以及 RingBuffer 数据结构及其伪共享优化,感兴趣的朋友可以进入仓库地址查看,更欢迎大家提出 Issue 和 PR 对代码提出意见或对其进行改进。




