defbisect_right(a, x, lo=0, hi=None, *, key=None): """Return the index where to insert item x in list a, assuming a is sorted. The return value i is such that all e in a[:i] have e <= x, and all e in a[i:] have e > x. So if x already appears in the list, a.insert(i, x) will insert just after the rightmost x already there. Optional args lo (default 0) and hi (default len(a)) bound the slice of a to be searched. """
if lo < 0: raise ValueError('lo must be non-negative') if hi isNone: hi = len(a) # Note, the comparison uses "<" to match the # __lt__() logic in list.sort() and in heapq. if key isNone: while lo < hi: mid = (lo + hi) // 2 if x < a[mid]: hi = mid else: lo = mid + 1 else: while lo < hi: mid = (lo + hi) // 2 if x < key(a[mid]): hi = mid else: lo = mid + 1 return lo
defbisect_left(a, x, lo=0, hi=None, *, key=None): """Return the index where to insert item x in list a, assuming a is sorted. The return value i is such that all e in a[:i] have e < x, and all e in a[i:] have e >= x. So if x already appears in the list, a.insert(i, x) will insert just before the leftmost x already there. Optional args lo (default 0) and hi (default len(a)) bound the slice of a to be searched. """
if lo < 0: raise ValueError('lo must be non-negative') if hi isNone: hi = len(a) # Note, the comparison uses "<" to match the # __lt__() logic in list.sort() and in heapq. if key isNone: while lo < hi: mid = (lo + hi) // 2 if a[mid] < x: lo = mid + 1 else: hi = mid else: while lo < hi: mid = (lo + hi) // 2 if key(a[mid]) < x: lo = mid + 1 else: hi = mid return lo
为何二分查找的左右落点不同
观察源码能发现,两个函数的主要差距在如下部分:
1 2 3 4 5 6 7 8 9 10 11
# bisect_right if x < a[mid]: hi = mid else: lo = mid + 1
# bisect_left if a[mid] < x: lo = mid + 1 else: hi = mid
实际上二者的差异就在于,当 a[mid] == x 时,应当向高半区迭代还是向低半区迭代。
对于希望落点在目标元素右侧的二分查找,当 a[mid] == x 时,应当向它的右侧查找,即 lo = mid + 1 。这意味着接下来的二分查找需要向比 x 更大的那些数迭代,这样就能保证 x 一定在最后结果的前面。注意到由于 + 1的缘故,查找结果并不是在最后一个目标元素上,而是指向它后一个元素。
类似的,对于希望落点在目标元素左侧的二分查找,当 a[mid] == x 时,应当向它的左侧查找,即 hi = mid 。这意味着接下来的二分查找需要向比 x 更小的那些数迭代,这样就能保证 x 一定在最后结果的后面
bisect 源码带来的一些提醒
不要忽略 mid 下标的元素
注意到 bisect 库中,无论哪种二分查找,都没有出现 hi = mid - 1 的写法。这是因为如果二分查找中同时使用 lo = mid + 1 和 hi = mid - 1 ,可能会忽略 mid 下标的元素,导致二分查找结果不正确。
原始序列中如果没有目标元素 x
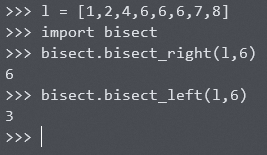
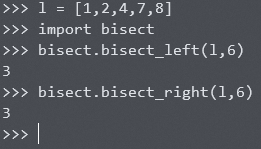
如果原始序列中没有目标元素 x ,查找结果会怎么样呢?以下示例能解释 bisect 库是怎么做的。
示例在升序序列 l = [1,2,4,7,8] 中查找元素6的位置。两种二分查找方法都返回了3,即元素7所在的位置。这意味着 bisect 库的二分查找在无法找到目标元素位置的时候,将在所有比目标值大的元素中,返回最接近目标元素大小的元素的下标。
这实际上是 lo = mid + 1 语句导致的。如果把代码改为 lo = mid 并且 hi = mid - 1 ,那么在无法找到目标元素位置的时候,将在所有比目标值小的元素中,返回最接近目标元素大小的元素的下标。